
Table of contents
| 자료 구조는 알고리즘의 기본이 되는 개념입니다. 실제로 실무에서도 많이 사용하기도 하므로 개념을 명확히 알고 있는 것이 중요합니다. |
자료 구조란?
자료 구조는 컴퓨터 과학에서 효율적인 접근 및 수정을 가능케 하는 자료의 조직, 관리, 저장
정확히 말해 데이터 값의 모임, 데이터 간의 관계, 데이터에 적용할 수 있는 함수나 명령을 의미한다.
신중히 선택한 자료구조는 보다 효율적인 알고리즘을 사용할 수 있게 한다.
자료구조의 종류
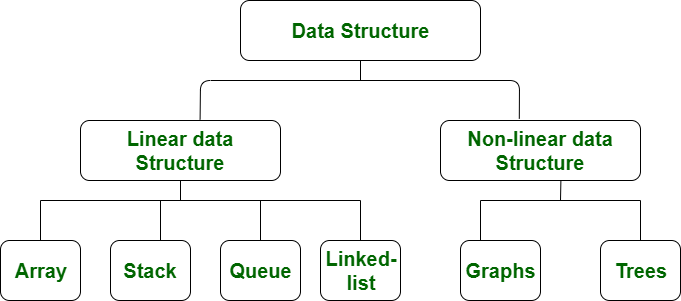
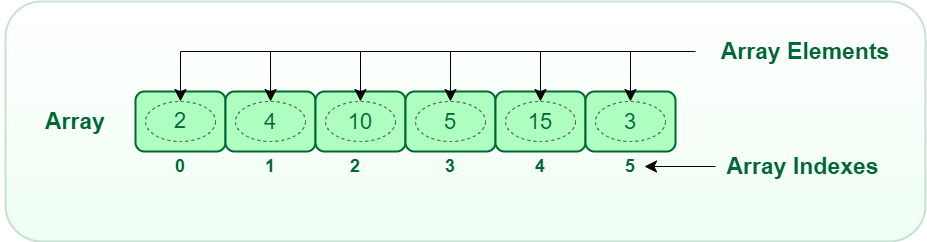
1. 배열(Array)
동일한 type의 데이터들을 저장하며 크기가 고정되어 있다.
인덱싱이 되어 있어 인덱스 번호로 데이터에 접근이 가능하다.
주로 다른 자료구조를 구축하기 위해 사용한다.(스택, 큐, 덱 등등..)
2. 스택(Stack)
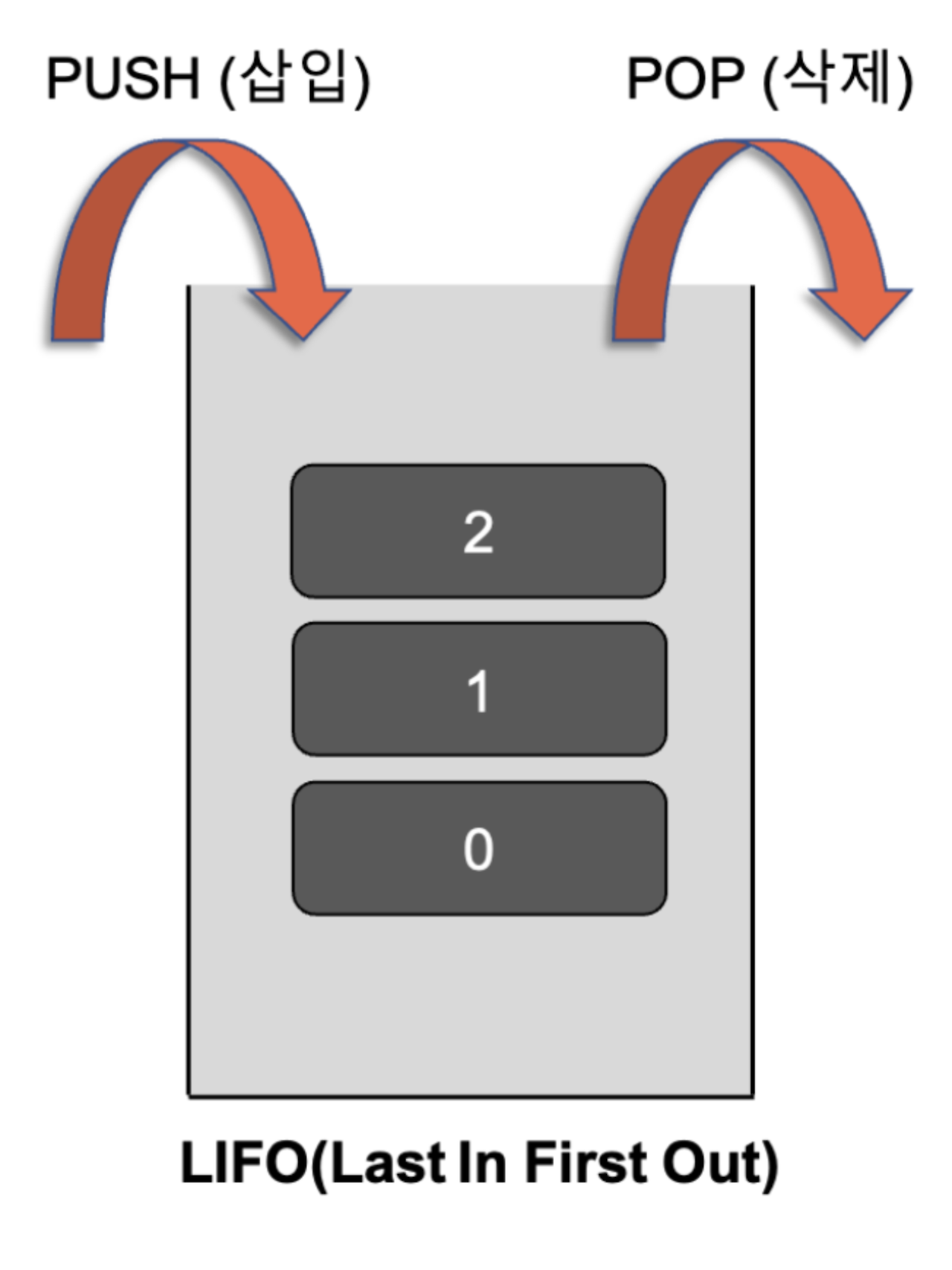
- 후입 선출, Last In First Out:LIFO
“쌓다”라는 의미로 데이터를 차곡차곡 쌓아 올린 형태로 가장 마지막에 삽입된 자료가 가장 먼제 삭제된다.
스택은 정해진 방향으로만 쌓을 수 있으며, top으로 정한 곳을 통해서만 접근할 수 있다.
새로 삽입되는 자료는 top이 가리키는 맨 위에 쌓이게 되며 자료를 삭제할 때도 top을 통해서 삭제가 가능하다.
사용 예시
- 웹 브라우저 방문 기록(뒤로 가기)
실행 취소(undo)
- 재귀함수
3. 큐(Queue)
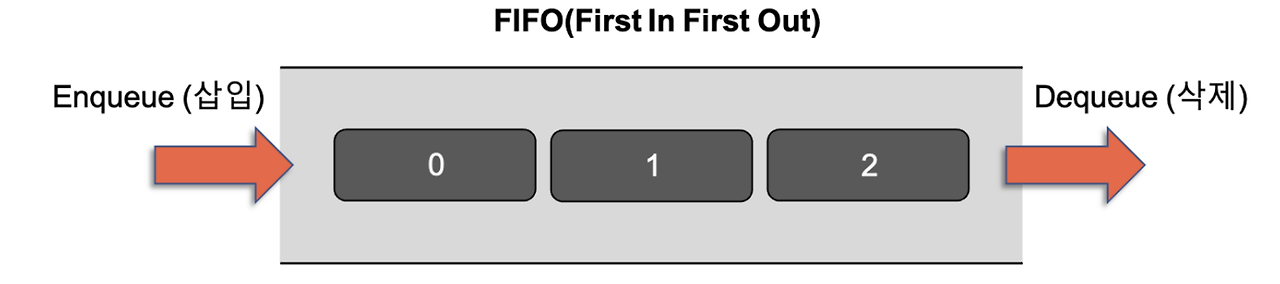
- 선입 선출, First In First Out:FIFO
한 쪽에서는 데이터 삽입, 다른 한 쪽에서는 데이터의 삭제만 가능하다.
Front: Dequeue시 삭제되는 데이터
Rear: 추가될 새로운 요소의 위치
- 예시
- BFS 알고리즘
- 프로세스 관리(JS의 콜백 큐)
- 프린터의 대기열
3-1. 우선순위 큐(Priority Queue, Heap)
우선순의 큐의 각 요소는 값과 우선순위, 총 2개의 데이터를 갖고 있다.
따라서 선형 큐와는 달리 우선순위가 높은 요소일수록 먼저 삭제되는 특징을 가지고 있으며 우선순위가 같은 데이터일 경우 삽입 순서를 따른다.
int와 같은 자료형을 사용한다면 큐에 있는 모든 원소 중에서 가장 큰 값이 top을 유지하도록, 우선순위가 가장 크도록 설계되어 있다.
내부적으로는 Heap 이라는 자료구조를 이용하고 있다.
- 예시
- 작업 스케줄링: 운영체제나 대규모 분산 시스템에서 중요한 작업이 먼저 처리되도록 작업 스케줄링에 활용된다. 예를 들어, CPU가 중요한 프로세스를 먼저 실행할 때 우선순위 큐를 사용할 수 있다.
- 이벤트 처리 시스템: 중요도가 다른 여러 이벤트를 처리할 때, 중요한 이벤트를 먼저 처리하기 위해 사용 가능하다.
- Struct를 이용해 원하는 대로 우선순위를 지정할 수 있다.
struct cmp {
bool operator()(int a, int b) {
return a > b;
}
};
a는 부모 노드이고, b는 현재 노드이다. 만약 부모 노드보다 현재 노드가 크다면 true가 반환되므로 swap이 발생, 즉 오름차순으로 정렬된다.
priority_queue<int, vector<int>, cmp> pq //다음과 같이 선언
3-2. 덱(Double-ended queue, Duque)
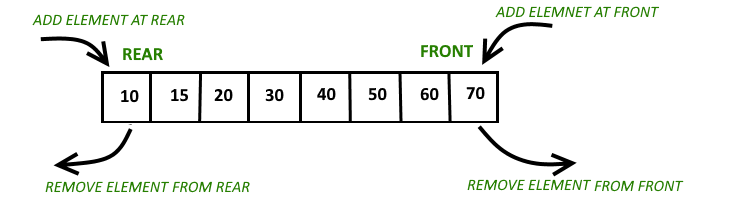
deque는 vector의 단점을 보완하기 위해 만들어졌다. Deque도 vector과 마찬가지로 배열구조이며 기존의 queue와 달리 앞뒤로 push가 가능하다.
Vector의 새로운 원소가 추가될 때 메모리 재할당 후 이전 원소를 복사하는 방식으로 인하여 원소 삽입 시 성능이 저하된다는 단점이 있지만, deque는 이러한 단점을 보완해 여러 개의 메모리 블록을 할당하고 이를 하나의 블록처럼 여긴다.
또한 메모리가 부족할 때 일정한 크기의 새로운 메모리 블록을 할당한다.
#include <deque>
deque<int> dq;
deque<int> dq(10); //default(0)으로 초기화된 10개의 원소를 가진 deque
deque<int> dq(10, 4); //4로 초기화된 10개의 원소를 가진 deque
- 예시
- 캐시(Cache): LRU(Least Recently Used) 캐시에서 주로 사용된다. 최근에 사용된 데이터를 양쪽 끝에 빠르게 삽입하거나 삭제할 수 있어 시간 복잡도를 줄일 수 있다.
4. 연결 리스트(Linked List)
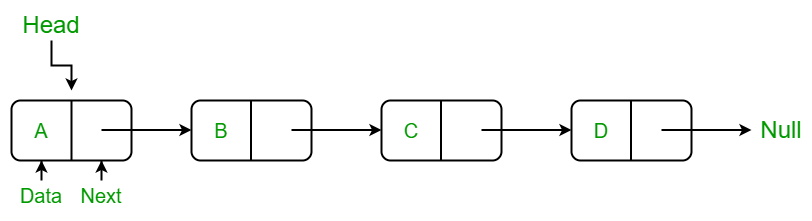
배열의 요소 뿐만 아니라 요소의 포인터 주소도 갖고 있다. 따라서 curser(iterator)를 이용해 주소값을 옮겨 다닐 수 있다. 또한 이를 활용해 가운데에 원소를 집어 넣거나 지울 수 있다.
- 예시
- 메모리 관리 시스템: 힙 메모리 관리에서 사용되는 빈 공간 리스트(free list)를 관리할 때, 연결 리스트를 사용하여 메모리 블록을 관리한다.
int main() { //리스트 선언 list<int> b; //리스트 포인터 선언 list<int>::iterator iter = b.begin(); //뒤쪽으로 요소 추가하기 for (int i = 0; i < 5; i++) { b.push_back(i); } //양 끝의 요소 제거하기 b.pop_back(); b.pop_front(); //중간에 요소 추가하기 (삭제는 함수만 erase로 바꿈) iter = b.begin(); int k = 2; //두번째 자리에 8 추가하기 for (int i = 0; i < k - 1; ++i) { ++iter; } b.insert(iter, 8); //전체 요소 출력하기 for (iter = b.begin(); iter != b.end(); iter++) { cout << *iter << " "; } return 0; }
- 메모리 관리 시스템: 힙 메모리 관리에서 사용되는 빈 공간 리스트(free list)를 관리할 때, 연결 리스트를 사용하여 메모리 블록을 관리한다.
4-1. Doubly Linked List

한방향이 아닌, 이전의 노드도 탐색할 수 있는 linked list
한 node 당 2개의 포인터가 존재한다.
그래프와 트리는 2부에서 진행합니다.